Kubernetets的核心架构原则
容器技术
namespace:隔离应用进程,给应用进程一个独立的运行环境,让进程之间不受干扰,完全封闭的环境独立的网络标识
cgroup:限制进程资源
有了namespace做隔离,有了cgroup限制资源,我们可以很安全将一个应用丢到某个隔离环境中运行,并且不对主机产生影响
应用要跑起来要overlay文件系统支持
什么是 Kubernetes(K8s)?
Kubernetes 是谷歌开源的容器集群管理系统,是 Google 多年大规模容器管理技术 Borg 的 开源版本,主要功能包括:
基于容器的应用部署、维护和滚动升级;
负载均衡和服务发现;
跨机器和跨地区的集群调度;
自动伸缩;
无状态服务和有状态服务;
插件机制保证扩展性。
命令式( Imperative)vs 声明式( Declarative)
声明式系统关注做什么
- 幂等性:状态固定,每次我我要你做事,请给我返回相同结果。
- 面向对象的:把一切抽象成对象
命令式系统关注如何做
Kubernetes:声明式系统
Kubernetes 的所有管理能力构建在对象抽象的基础上,核心对象包括:
Node:计算节点的抽象,用来描述计算节点的资源抽象,健康状态等;
Namespace:资源隔离的基本单位,可以简单理解为文件系统中的目录结构;
Pod:用来描述应用实例,包括镜像地址,资源需求等。Kubernetes中最核心的对象,也是打通应用和基础架构的秘密武器;
- Service:服务如何将应用发布成服务,本质上是负载均衡和域名服务的声明。
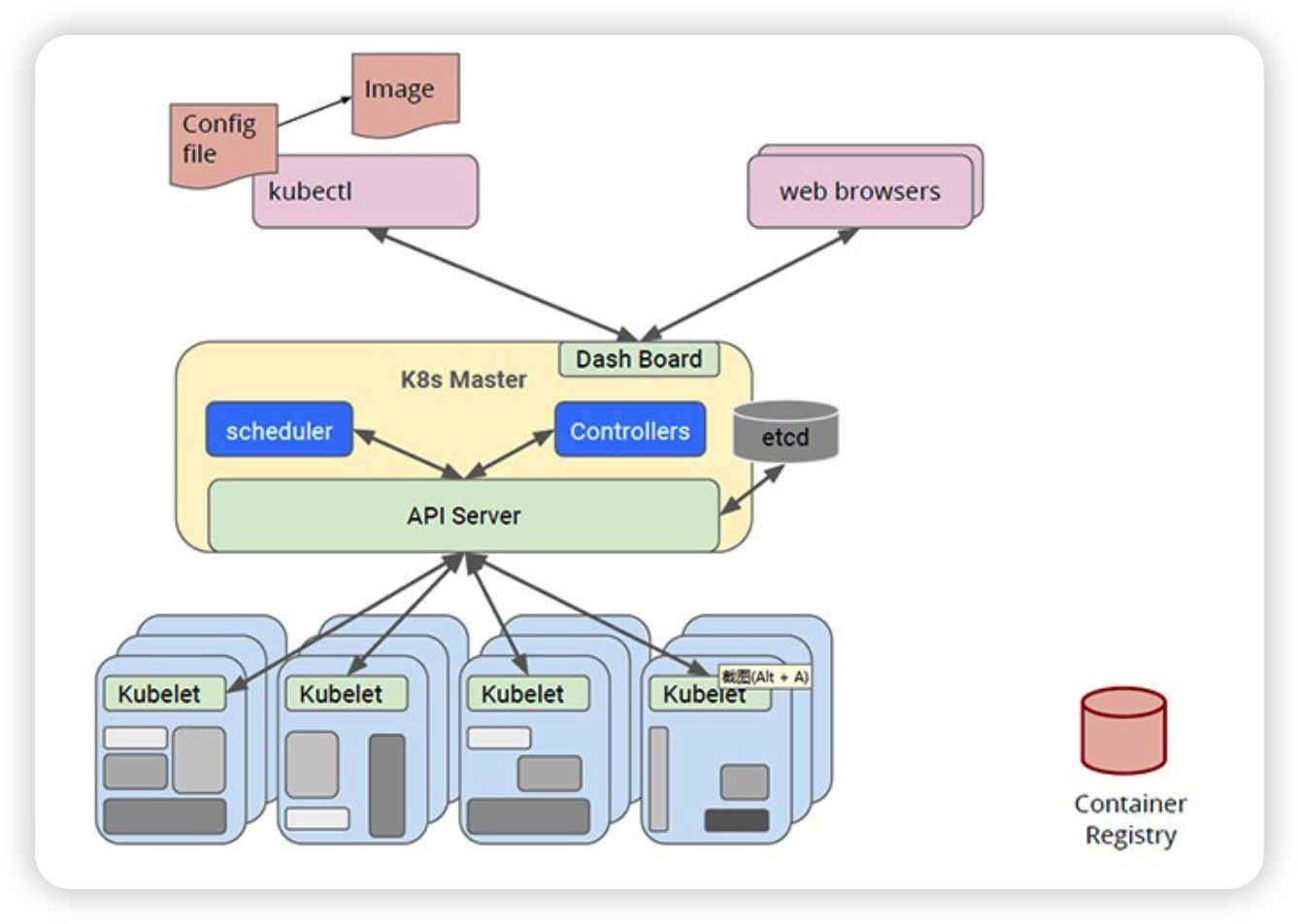
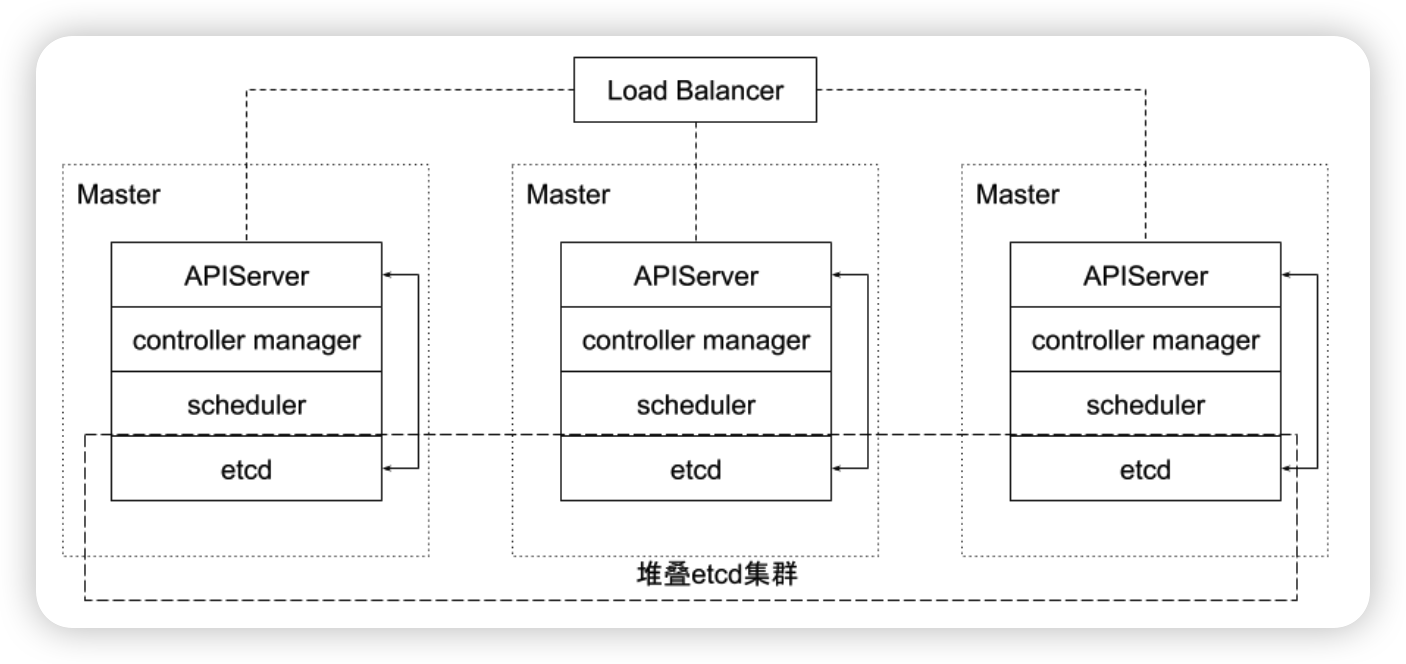
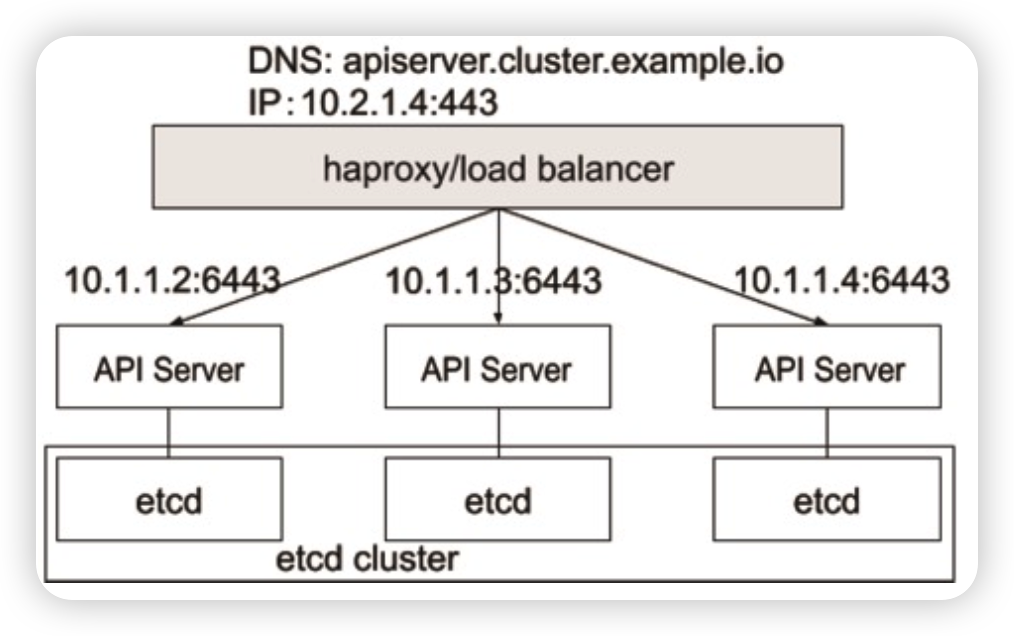
Kubernetes 采用与 Borg 类似的架构
etcd
etcd 是 CoreOS 基于 Raft 开发的分布式 key-value 存储,可用于服务发现、共享配置以及一致性保障 (如数据库选主、分布式锁等)。
- 基本的key-value存储;
- 监听机制 watch;
- key的过期及续约机制,用于监控和服务发现;
- 原子CAS和CAD,用于分布式锁和leader选举。
raft协议: 确保数据一致性
etcd每个member都有三种身份:leader、follower(启动时:跟随者)、candidate(候选人、竞选者)
为了从member中选出一个主来,然后所有的写操作都是通过主来的,其它实例变成follower的角色来听从主的吩咐。
etcd启动时角色为follower,如果有leader则跟随,否则,角色变成candidate,通过拉票的方式选主,leader选举出来后,其它实例都变成follower角色,leader会一直给follower发送心跳来维持leader的地位。所有的写请求leader会将数据通过下次心跳一起发送给follower,follower接受到心跳之后会返回log给leader,leader确认后,这一次数据将写入(commit)完成。
支持watch机制,
根据你的请求的条件,返回当前的结果,并且不会断开当前client的链接,保持长连接,接下来当前请求结果有变更,会通过enevt机制将结果推送
直接访问etcd的数据
- 通过etcd进程查看启动参数
- 进入容器
- 到主机namespace查看cert信息
- 进入容器查询数据
$ export ETCDCTL_API=3
$ etcdctl --endpoints https://localhost:2379 --cert /etc/kubernetes/pki/etcd/server.crt --key /etc/kubernetes/pki/etcd/server.key --cacert /etc/kubernetes/pki/etcd/ca.crt get --keys- only --prefix /
- 监听对象变化
$ etcdctl --endpoints https://localhost:2379 --cert /etc/kubernetes/pki/etcd/server.crt --key /etc/kubernetes/pki/etcd/server.key --cacert /etc/kubernetes/pki/etcd/ca.crt watch --prefix /registry/services/specs/default/mynginxAPIServer
kube-APIServer 是 Kubernetes 最重要的核心组件之一,主要提供以下的功能:
- 提供集群管理的 REST API 接口,包括:
- 认证 Authentication;
- 授权 Authorization;
- 准入 Admission(Mutating & Valiating)。
- 提供其他模块之间的数据交互和通信的枢纽(其他模块通过 API Server 查询或修改数据,只有 API Server 才直接操作 etcd)。
- APIServer 提供 etcd 数据缓存以减少集群对 etcd 的访问。
Apiserver是整个集群的核心,接受了所有的请求,并且所有的数据库读写都是从apiserver过
只有apiserver可以访问etcd,因为apiserver在访问etcd时构建了一个在apiserver的缓存,所以对于任意的客户端访问apiserver的时候,数据时不穿透APIserver的,APIserver会把缓存直接返回,etcd支持watch,有任意变化都会以通知形式告诉apiserver,理论上从apiserver获取的数据都是最新的数据。同理,apiserver也支持watch
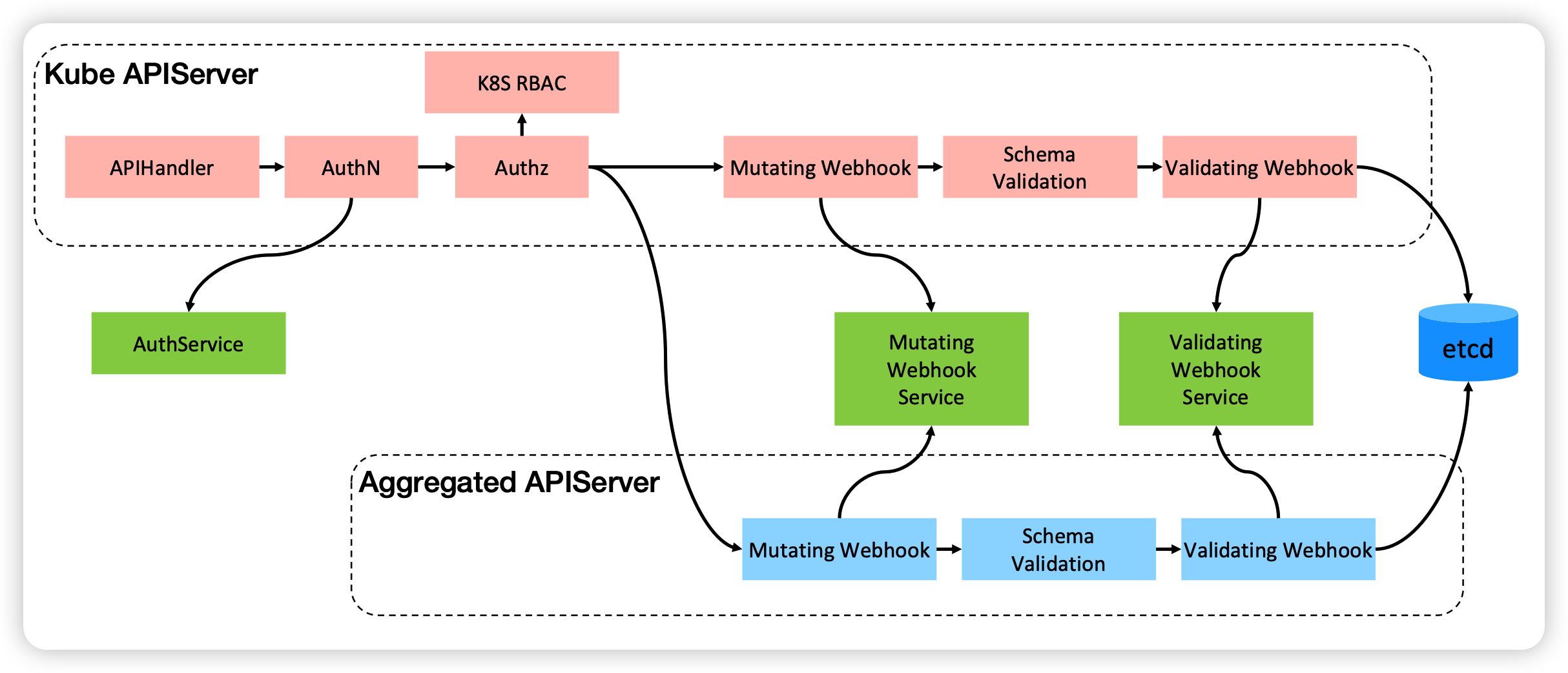
上面时标准APIserver,下面是二次开发
Controller Manager
- ControllerManager是集群的大脑,是确保整个集群动起来的关键;
- 其作用是确保Kubernetes遵循声明式系统规范,确保系统的真实状态(ActualState)与用 户定义的期望状态(Desired State 一直);
- ControllerManager是多个控制器的组合,每个Controller事实上都是一个controlloop, 负责侦听其管控的对象,当对象发生变更时完成配置;
- Controller配置失败通常会触发自动重试,整个集群会在控制器不断重试的机制下确保最终一 致性( Eventual Consistency)。
控制器的工作流程
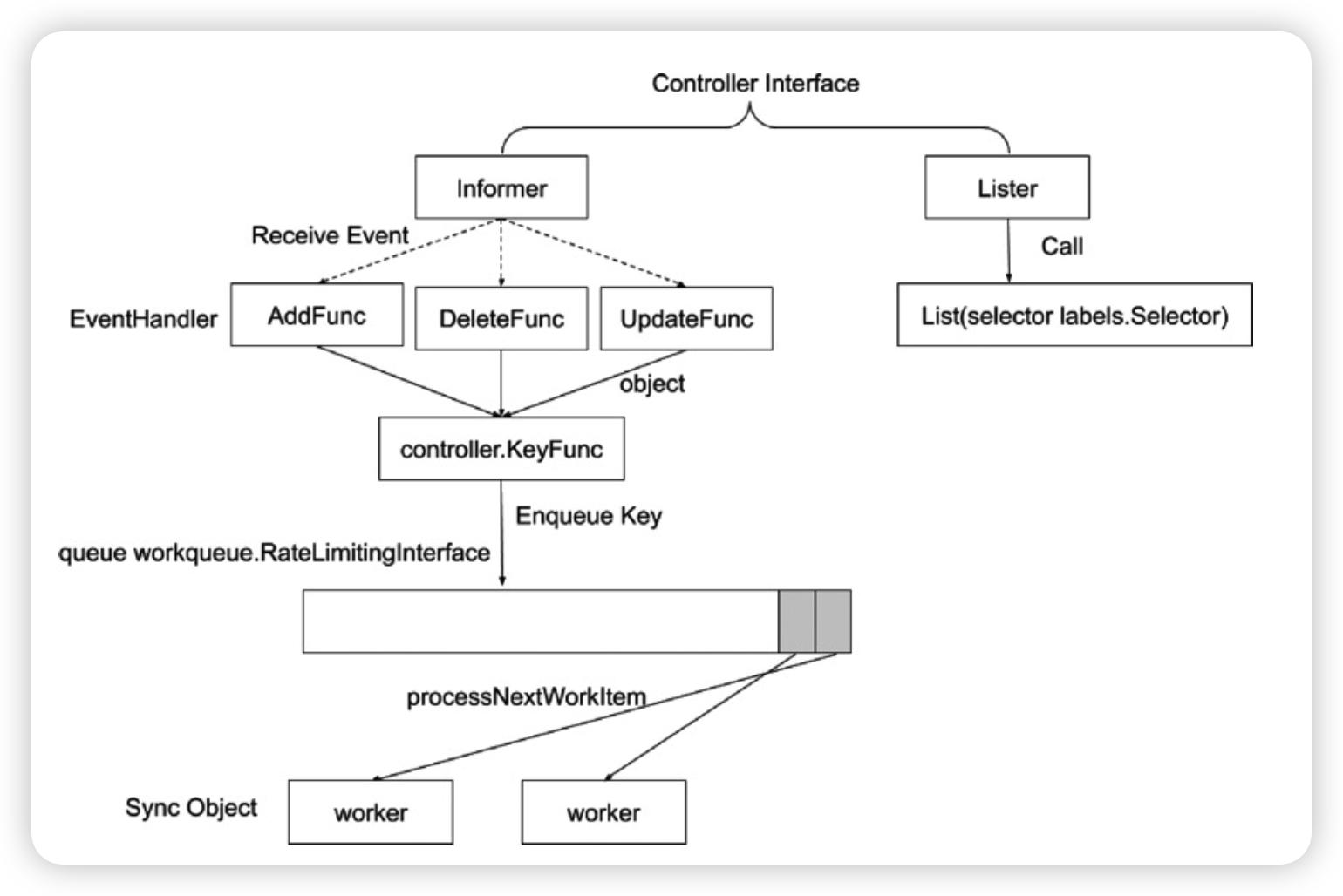
生产者消费者模式,任何的控制器会维护一个队列
Scheduler
特殊的 Controller,工作原理与其他控制器无差别;
Scheduler 的特殊职责在于监控当前集群所有未调度的Pod,并且获取当前集群所有节点的健康 状况和资源使用情况,为待调度 Pod 选择最佳计算节点,完成调度。
调度阶段分为:
- Predict:过滤不能满足业务需求的节点,如资源不足,端口冲突等。
- Priority:按既定要素将满足调度需求的节点评分,选择最佳节点。
- Bind:将计算节点与Pod绑定,完成调度。
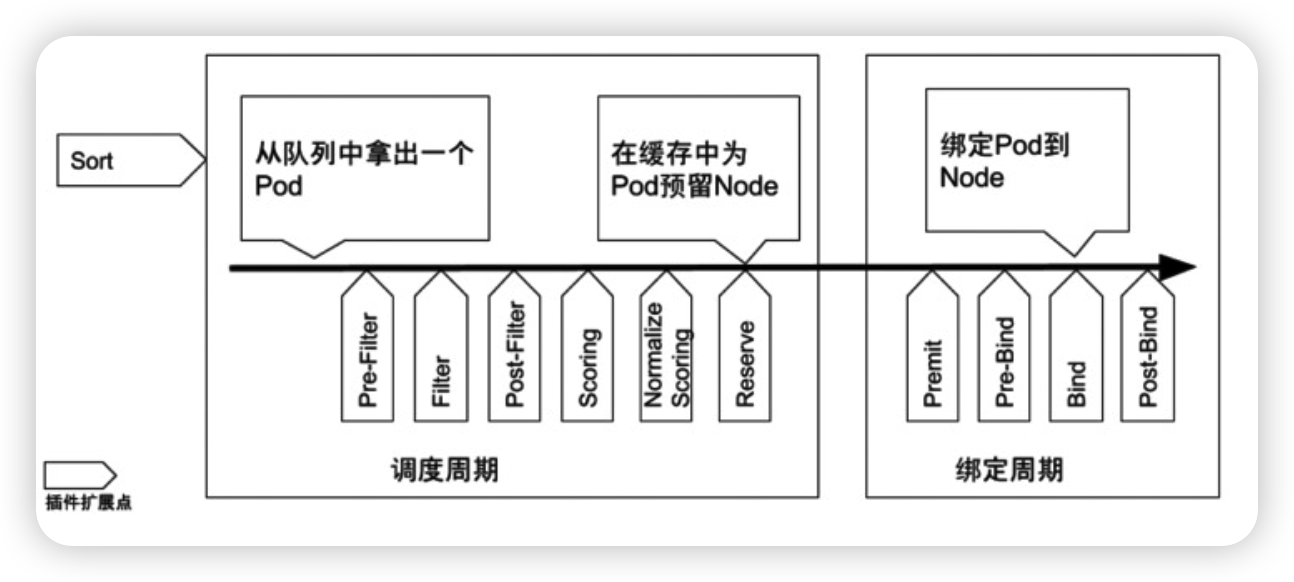
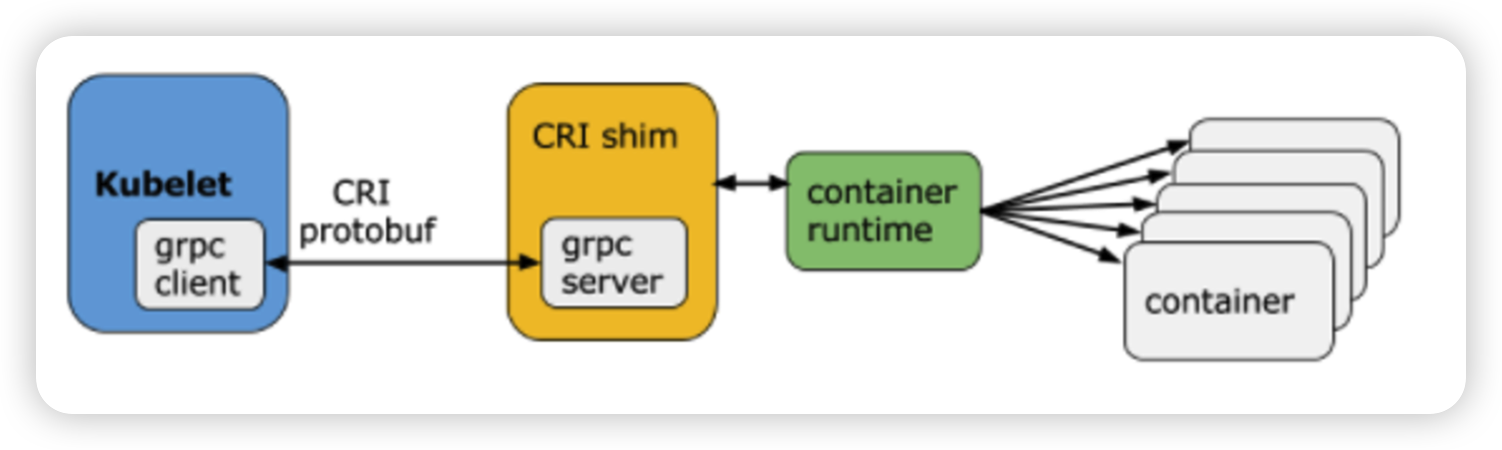
Kubelet
Kubernetes 的初始化系统(init system)
从不同源获取Pod清单,并按需求启停Pod的核心组件:
Pod 清单可从本地文件目录,给定的 HTTPServer 或 KubeAPIServer 等源头获取;
Kubelet 将运行时,网络和存储抽象成了 CRI,CNI,CSI。
负责汇报当前节点的资源信息和健康状态;
负责Pod的健康检查和状态汇报。
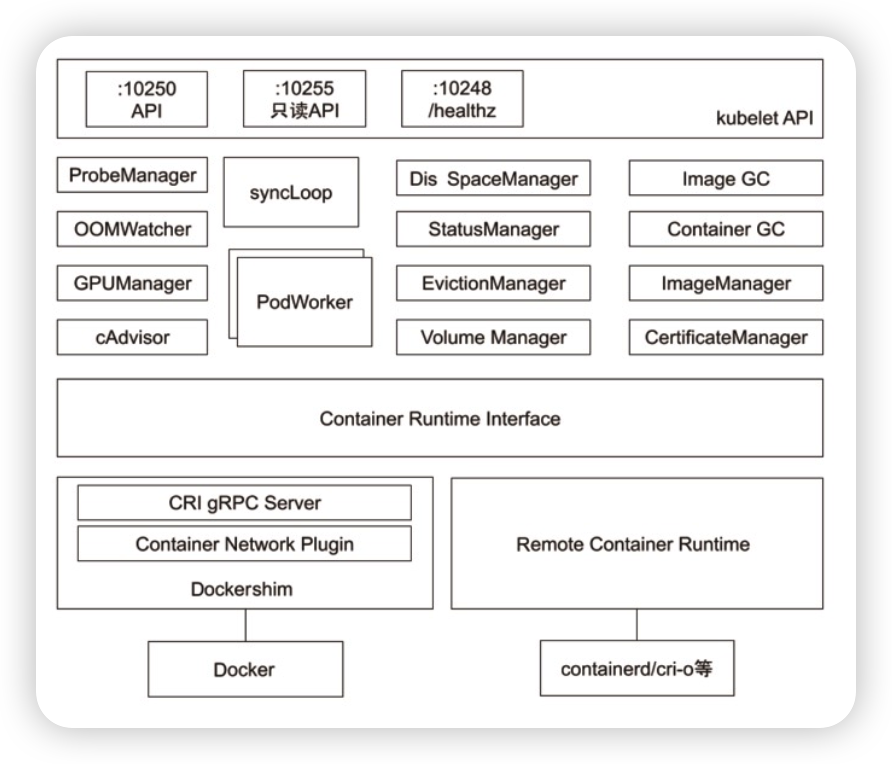
理论上把用户进程拉起来,通过namespace和cgroup做资源控制,通过replay把docker image把overlay fs拉起来,然后通过网络插件把网络配起来,K8S为了标准化,把这些借口抽象成CRI, CNI, CSI
kubelet是systemd里面的一个service
配置文件读取路径:/etc/kubenetes/manifests
kubelet除了watchapiserver,还可以扫描本地目录加载pod
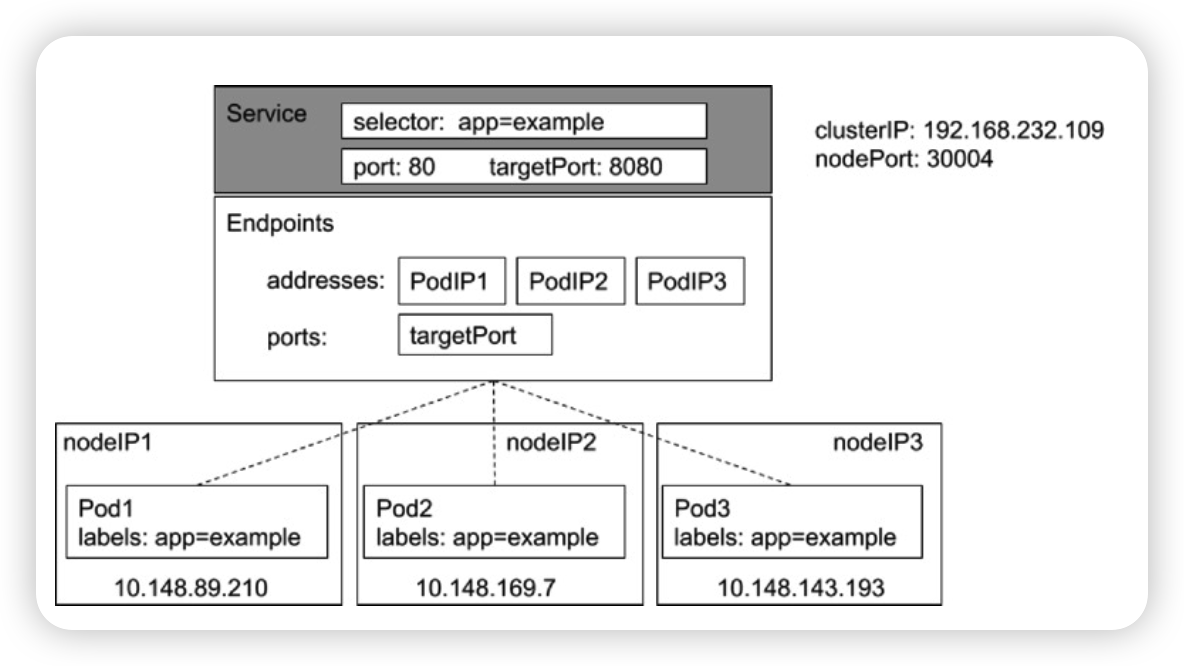
Kube-Proxy
监控集群中用户发布的服务,并完成负载均衡配置。
每个节点的Kube-Proxy都会配置相同的负载均衡策略,使得整个集群的服务发现建立在分布 式负载均衡器之上,服务调用无需经过额外的网络跳转(Network Hop)。
负载均衡配置基于不同插件实现: •
userspace。
操作系统网络协议栈不同的 Hooks 点和插件:
iptables;
ipvs。
Add-ons
kube-dns:负责为整个集群提供 DNS 服务;
Ingress Controller:为服务提供外网入口;
MetricsServer:提供资源监控;
Dashboard:提供 GUI;
Federation:提供跨可用区的集群;
Fluentd-elasticsearch:提供集群日志采集、存储与查询。
API 设计原则
- Kubernetes 将业务模型化,这些对象的操作都以 API 的形式发布出来,因此其所有 API 设计都是声明式的。
- 控制器的行为应该是可重入和幂等的,通过幂等的控制器使得系统一致朝用户期望状态努力,且结果稳定。
- 所有对象应该是互补和可组合的,而不是简单的封装。通过组合关系构建的系统,通常能保持很好的高内聚、松耦合特性。
- API 操作复杂度应该与对象数量成线性或接近线性比例,这制约了系统的规模上限,如果操作复杂度和 对象成指数比例,那么随着对象的增加,操作的复杂度会迅速上升到用户无法接受的程度。
- API 对象状态不能依赖于网络连接状态。众所周知,在分布式环境下,网络连接断开是经常发生的事情, 如果希望API对象的状态能应对网络的不稳定,那么 API 对象的状态就不能依赖于网络连接状态。
- 尽量避免让操作机制依赖于全局状态,因为在分布式系统中要保证全局状态的同步是非常困难的。
架构设计原则
- 只有apiserver可以直接访问etcd存储,其他服务必须通过KubernetesAPI来访问集群状态;
- 单节点故障不应该影响集群的状态;
- 在没有新请求的情况下,所有组件应该在故障恢复后继续执行上次最后收到的请求(比如网络分区 或服务重启等);
- 所有组件都应该在内存中保持所需要的状态,apiserver将状态写入etcd存储,而其他组件则通过 apiserver 更新并监听所有的变化;
- 优先使用事件监听而不是轮询。



