InfluxDB
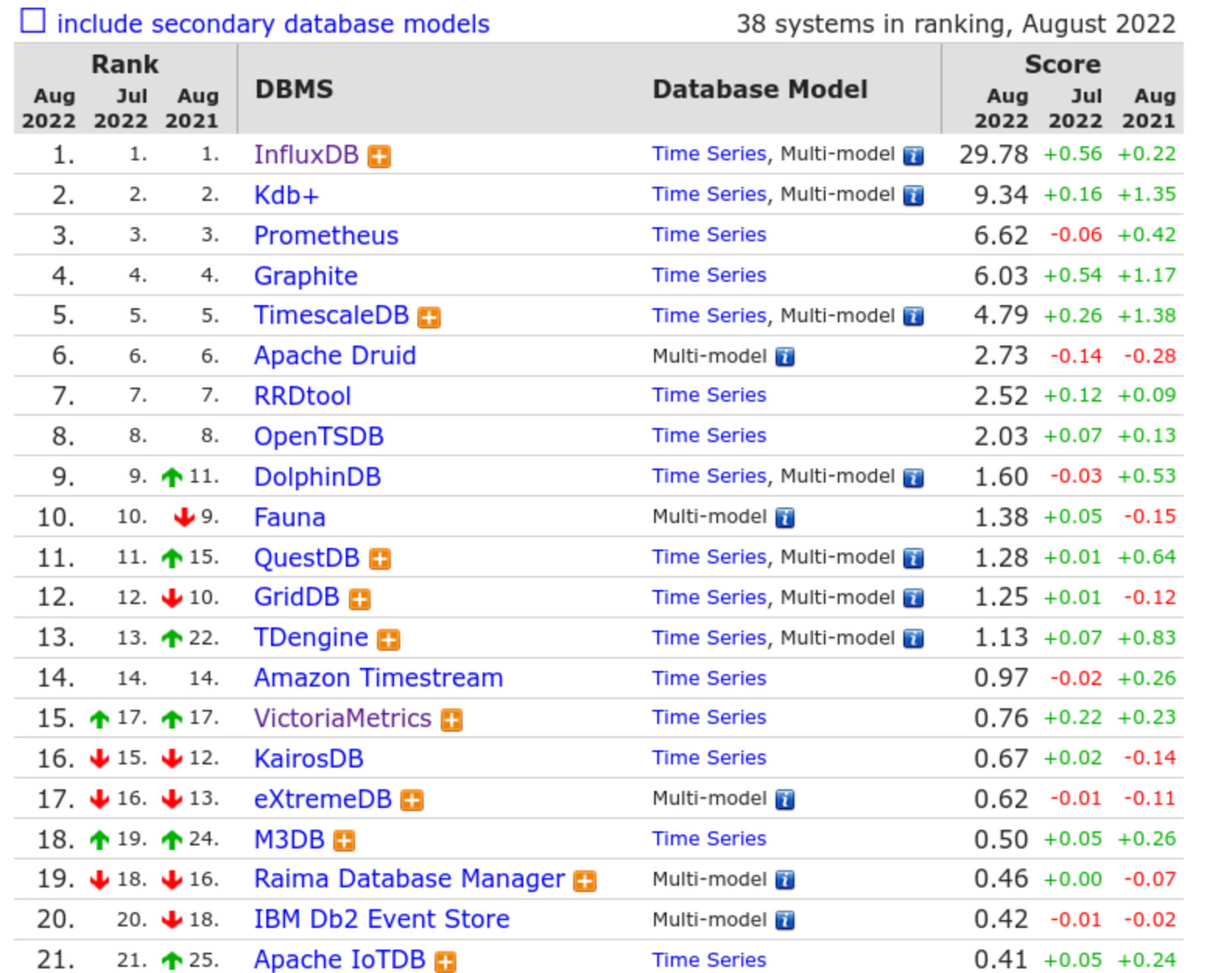
- InfluxDB是时序数据库中应用比较广泛的一种,在DB-Engines TSDB rank中位居首位,可见InfluxDB在互联网的受欢迎程度是非常高的
它是go语言开发的数据库,InfluxDB自发布至今,已经有两个版本,InfluxDB1.x系列提供一种类似SQL的查询语言InfluxQL,用于数据交互。2019年1月新推出的influxDB2.0 alpha版本,主推全新的查询语言Flux,支持TICK架构, TICK 整合成一个整体,将时序数据库、UI、仪表盘工具以及后台处理和监控代理置于一组 API 后面。在 2020 年底推出了InfluxDB 2.0 正式版本,该版本又分为InfluxDB Cloud 和 InfluxDB OSS两个系列。
InfluxDB 2.0还与InfluxDB Cloud紧密集成,InfluxDB Cloud是无服务器,弹性可扩展,完全托管的时间序列数据库平台。借助共享 API,您可以轻松地在 InfluxDB 2.0 和 InfluxDB Cloud 之间移动数据和工作负载,并且可以将它们作为单个时间序列平台的组件一起使用,从而为开发人员提供灵活性和工具,以满足不断变化的业务和应用程序需求。
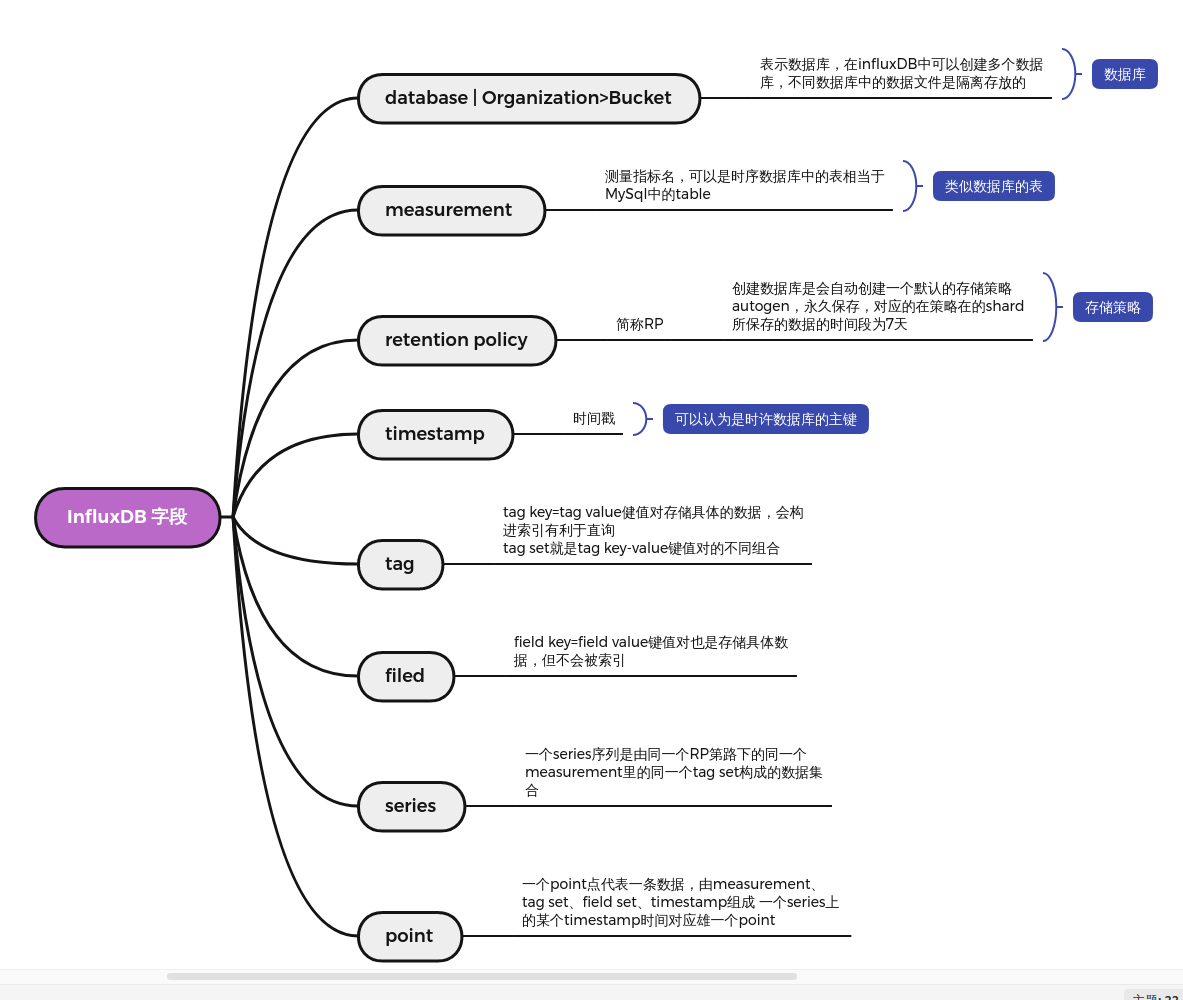
时序数据库与我们熟悉的关系型数据库有所不同,首先需要了解一下 InfluxDB 中字段的含义
v1.x
v2.x
V2具有以下几个概念:
timestamp、field key、field value、field set、tag key、tag value、tag set、measurement、series、point、bucket、bucket schema、organization
新增的概念:
bucket:所有 InfluxDB 数据都存储在一个存储桶中。一个桶结合了数据库的概念和存储周期(时间每个数据点仍然存在持续时间)。一个桶属于一个组织
bucket schema:具有明确的schema-type的存储桶需要为每个度量指定显式架构。测量包含标签、字段和时间戳。显式模式限制了可以写入该度量的数据的形状。
organization:InfluxDB组织是一组用户的工作区。所有仪表板、任务、存储桶和用户都属于一个组织。
TICK 架构分析与各组件功能介绍
TICK 架构 是 InfluxData 平台的组件的集合首字母缩写,该集合包括 Telegraf、InfluxDB、Chronograf 和 Kapacitor。TICK 架构以及各组件分工情况如图所示:
V2版本主要有这么几个特性:
1.一个可执行文件
chronograf kapacitor influxdb都整合到一起了,一个二进制可执行文件执行后,监听9999她口,这个端口既是@b贪面的端商,料练袋库
的监听端口。
2,权限全增强,新增了token.可以使用token进行数据读写操作
3,DSL又改了!目的是为了通过这一个DSL来解决定时、流任务,数据查询等多种操作,并且相比tck.能执行的操作更多。
4,接口返回数据的格式改为csv,并且可以使用uxQL来自定义返回数据的格式与字段
5,增加了类似prometheus的scrape功能,不过似乎默认是1O秒的采集间隔,这样可以直接采集prometheus exporter.上的数据,如果你使
用1.7或更低版本,可能需要在prometheus中采集数据时使用remote write的功能,将致据点写入influxdb。
现在influxdb v2直接可以实现这个采集的操作
6,流任务更加直观。现在你可以查询数据时,把查询操作直接保存成定时任务,然后将生成的数据backfil进influxdb中。
并且这个定时任务的管理器功能更加强大,你不仅可以设置定时执行,还能立刻执行
OSS 2.x包括1.x兼容的/query和/write端点
它自带有一个包含 Settings、Dashboards、Tasks、Alerts 等功能的 web 后台



