InfluxDB 2.0 开源正式发布
===================
By Russ Savage / Nov 10, 2020 / InfluxDB, Community, Developer, Flux, InfluxDB Templates
今天,我们很自豪地宣布,InfluxDB开源2.0现已正式向所有人开放。这是一条漫长的道路,如果没有我们社区的惊人支持和贡献,我们就无法做到这一点。这标志着InfluxDB平台的新时代,但它确实只是一个开始。
在我们谈论未来之前,让我们来看看我们的团队一直在研究的一些惊人的新功能。
默认情况下易于部署和安全
对于任何熟悉我们现有的开源产品(亲切地称为Telegraf,InfluxDB,Chronograf和Kapacitor的TICK Stack缩写)的人来说,您可能会注意到的第一件事是只有一个二进制文件需要下载和安装。
新的 InfluxDB 现在在单个二进制文件中包含时间序列数据平台中所需的一切。这简化了部署和设置体验,同时保持了各个组件的强大功能和灵活性。
单个二进制文件意味着它也更容易保护,因此我们默认使InfluxDB安全。对InfluxDB的每个请求都伴随着一个可以撤销的身份验证令牌,并且内置用户界面使用用户名和密码进行保护。
通过这些更改,您再也不必担心意外地将存储在 InfluxDB 中的数据暴露给公共互联网。
易于部署,易于管理,默认情况下是安全的。开发人员期望从现代开发平台获得这些东西,InfluxDB也不例外。
下一代数据探索和分析
我们知道开发人员尽快掌握数据的重要性。我们从社区中不断听到的一件事是,Chronograf(TICK Stack的“C”)使得快速查看进入系统的时间序列数据的形状变得非常容易,并简化了许多常见的管理任务。
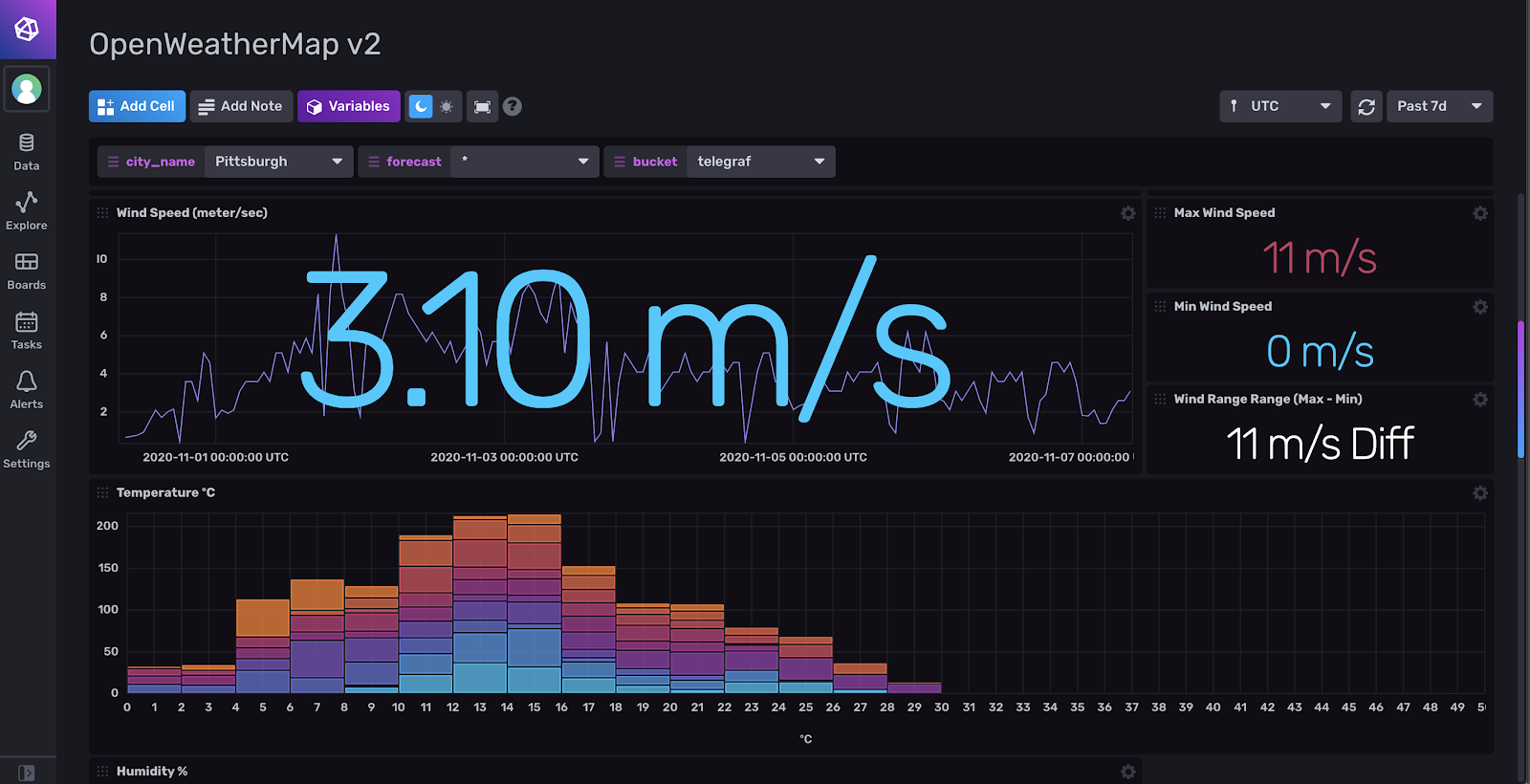
InfluxDB 开源 2.0 通过全新的数据资源管理器、其他可视化类型以及专为时序数据构建的强大新查询语言 Flux 延续了这一体验。您可以快速浏览所有测量值、字段和标签,并将常见转换应用于该数据,而无需使用键盘。
以下是我们新的数据资源管理器的外观:
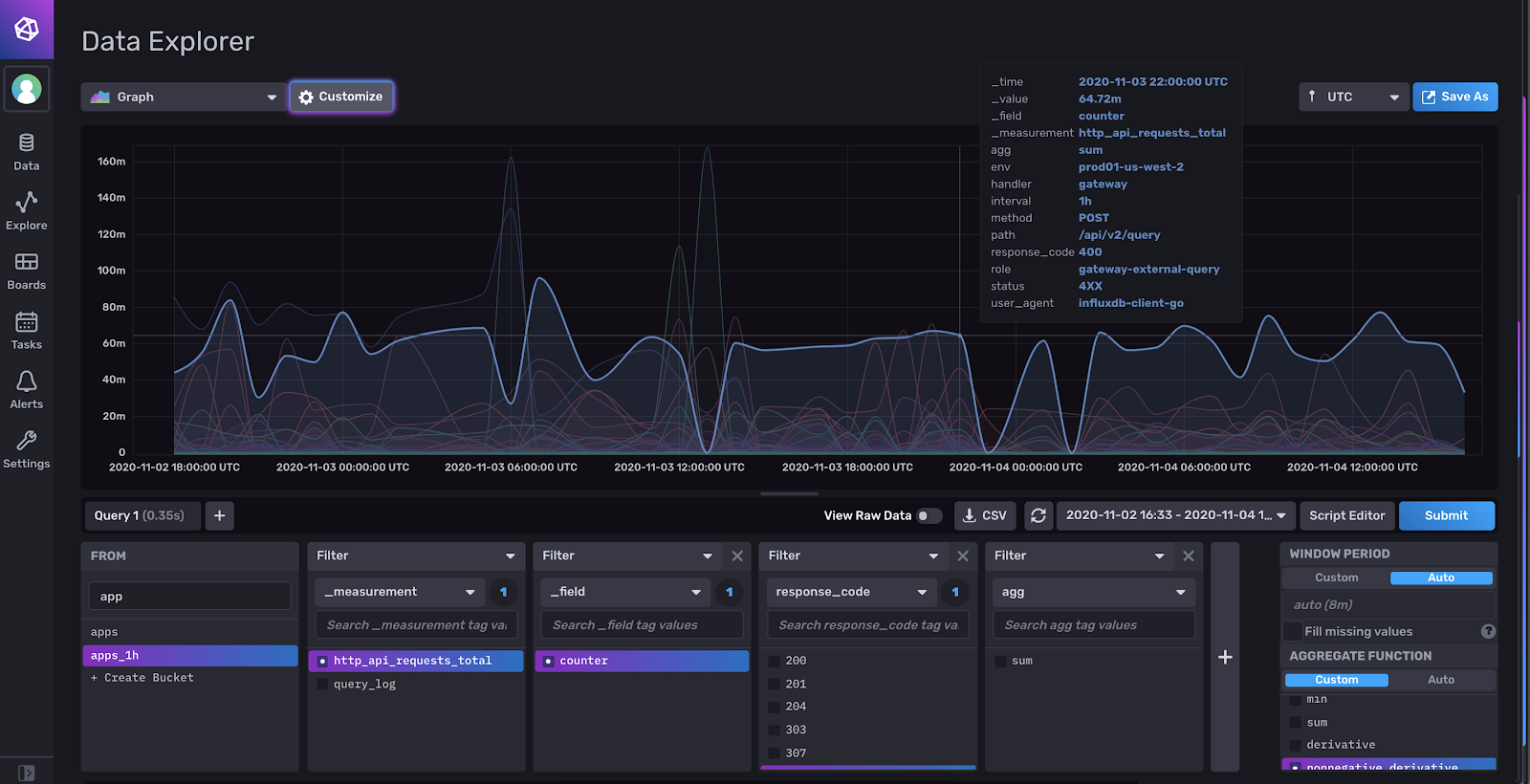
当然,对于那些希望释放其数据全部潜力的人来说,我们提供了一个脚本编辑器,其中包括自动完成,实时语法检查以及大量示例和文档,以帮助您入门。此编辑器在 InfluxDB Data Explorer、Dashboards 和 Tasks 中使用,并使用 Monaco,与 Visual Studio Code 中的编辑器相同。
等等,但是您已经拥有大量基于InfluxQL构建的应用程序和集成?没问题。InfluxDB 2.0 旨在替代您现有的 InfluxDB 实例。这意味着,如果您使用外部可视化工具进行仪表板操作或将数据写入数据库,则在升级后,该工具仍可正常工作。当然,我们建议将这些连接迁移到最新的 v2 API,但它们将继续按原样正常工作。向后兼容的 API 可帮助您根据需要快速移动。
Flux:下一代数据处理语言,可在数据所在的位置处理数据
许多用户喜欢通过InfluxQL(我们类似SQL的查询语言)访问数据的简单性。作为通往平台的简单入口,这是体验InfluxDB强大功能的好地方。但是,随着时间的推移,随着用例的复杂性越来越超出简单的选择语句,因此也带来了挑战。因此,开发人员最终编写了自定义应用程序逻辑,以执行现代应用程序通常需要的许多复杂转换。
这有一些缺点。首先,我们希望构建一个平台,使开发人员的工作效率更高,而花费在编写通用数据转换逻辑上的任何时间都是从为他们自己的用户和客户建立价值中花费的时间。第二个缺点是性能。数据从存储层获取的距离越远,转换往往会变得越慢。
Flux的核心就是解决这些问题。Flux不是一种类似SQL的语言;它是一种类似于JavaScript或Python的函数式编程语言。这意味着您可以像编程应用程序一样自定义和构建查询,将通用逻辑分离到可重用的函数和库中,从而减少需要编写的代码总量。该代码也尽可能靠近存储层执行,直接向下推送许多操作,从而为您提供最快的系统性能。
数据更好地结合在一起
Flux 还构建为处理不仅仅是时间序列数据(尽管这是它的主要工作)。它可以直接从SQL数据存储中提取数据,例如Postgres,Microsoft SQL Server,SQLite和SAP Hana以及基于云的数据存储,如Google Bigtable,Amazon Athena和Snowflake。这使您可以丰富时序数据以提供额外的上下文。以下是一些示例:
- 对于 IoT 用户,Flux 允许您将来自传感器的时间序列数据与来自制造商、型号、设备使用年限或里程等关系表的信息相结合。
- 对于真实用户监控 (RUM),您可以使用 Flux 查找客户 ID 并连接客户名称、定价计划以及公司名称和位置等公司数据。
- 在IT基础设施监控中,Flux可以将服务器ID解析为软件版本和配置参数。
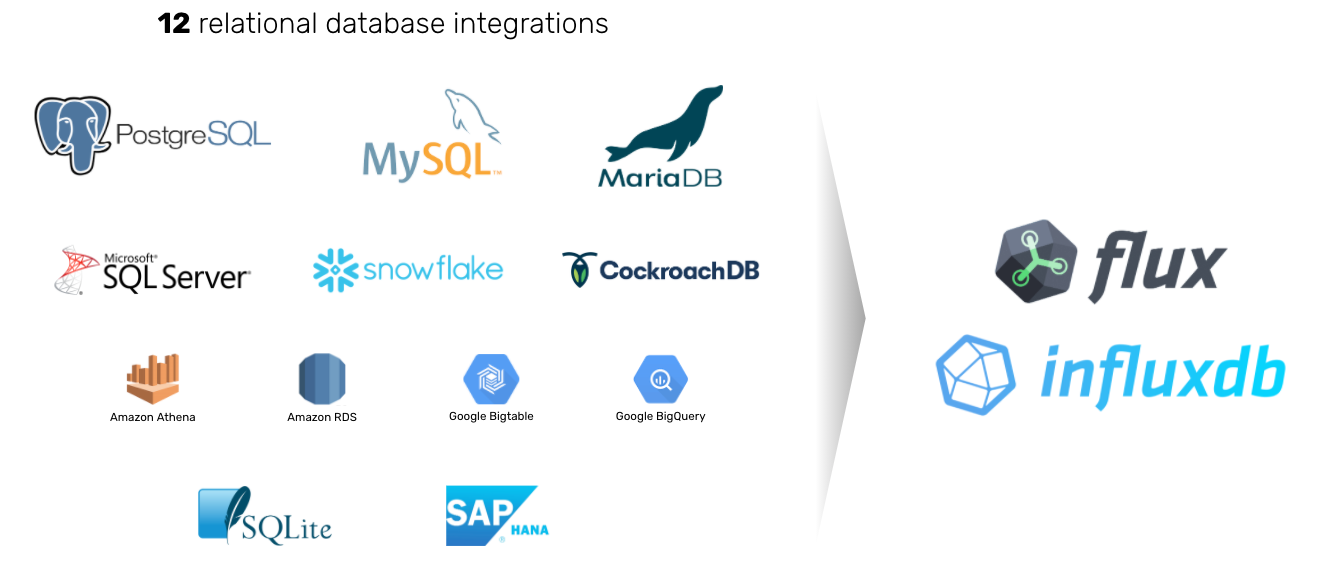
InfluxDB 和 Flux 可让您使用关系数据库来丰富时间序列数据
时间与空间相遇:使用通量的地理时态查询
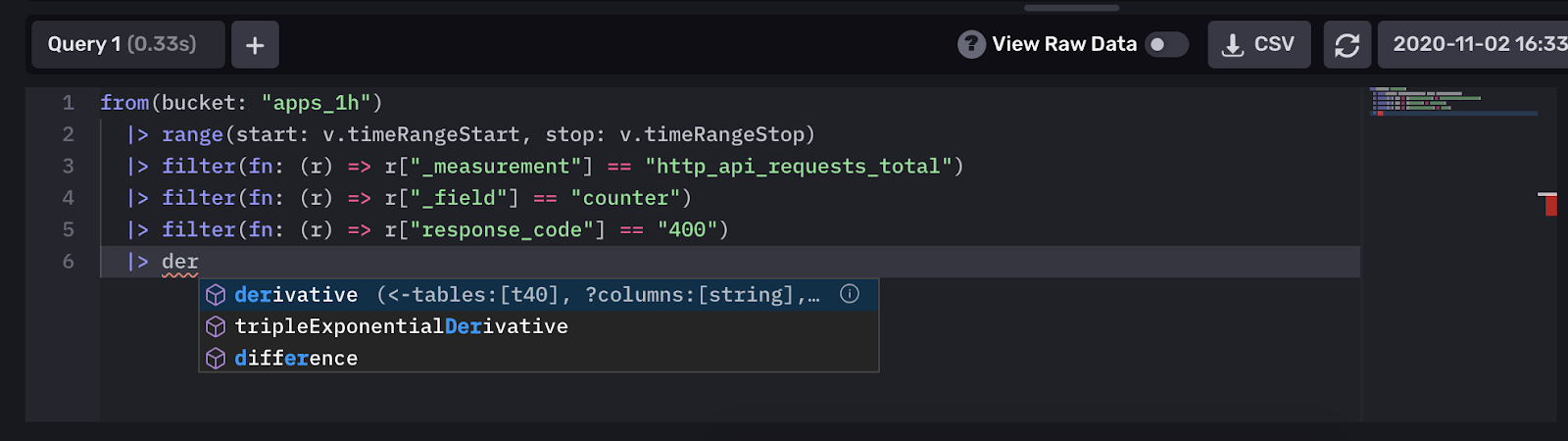
Flux 还允许您执行地理时态查询,因此您可以按时间和位置进行过滤。这对于许多需要跟踪移动设备或车辆的物联网用例至关重要。例如,下面的简单 Flux 查询允许您查询以三角形为界的所有点,三个坐标处的点。
`from(bucket: "example-bucket")
|> range(start: -1h)
|> filter(fn: (r) => r._measurement == "example-measurement")
|> geo.filterRows(
region: {
points: [
{lat: 40.671659, lon: -73.936631},
{lat: 40.706543, lon: -73.749177},
{lat: 40.791333, lon: -73.880327}
]
}
)`Copy使用上面的查询,您将获得以下可视化效果的数据:
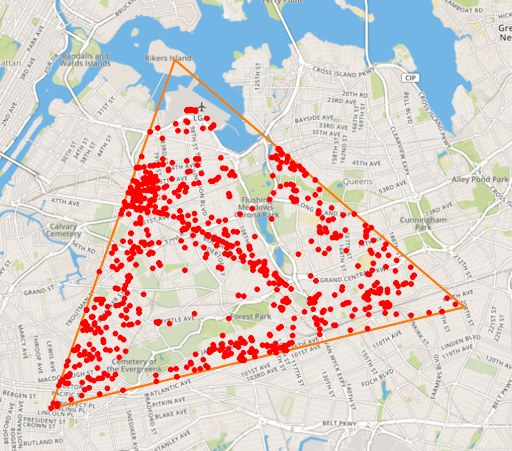
Flux 的地理时态库允许您按位置和时间进行查询
开发人员寻找的不仅仅是查询其数据的能力。他们想用它来建造。Flux 为我们的社区提供了使用数据分析和构建应用程序的最快、最强大的方法,我们迫不及待地想让您尝试一下。
计算指标、缩减采样等的后台处理
以交互方式处理数据可以提供强大的见解,但在现代系统中,这些交互式查询仅占整体处理的一小部分。流入应用程序的大多数数据在与其他信息结合使用以生成有关正在发生的事情的知识时会更加强大。该处理需要在后台持续可靠地进行,同时专注于利用见解。
InfluxDB 2.0包含一个名为Messions的强大新后台处理系统,该系统是使用与访问平台中存储的数据相同的Flux语言构建和执行的。这些任务可以执行许多强大的操作,包括聚合经常访问的指标以提高仪表板的性能,根据存储在完全不同系统中的数据计算自定义指标,或对数据进行缩减采样以节省长期存储费用。
还可以利用任务自动将数据推送到其他系统,从而对数据进行通知或警报。因为它们基于 Flux 语言,所以当我们添加新的库、功能或工具时,可以在任务中自动利用这些库、功能或工具。
InfluxDB任务在概念上类似于Kapacitor(TICK中的“K”)。但与Kapacitor不同的是,Kapacitor使用一种名为TICKscript的语言,该语言与Chronograf中使用的InfluxQL分开,Tasks使用Flux。这简化了开发人员的工作,因为他们可以对数据资源管理器和仪表板中的查询以及任务中的数据处理使用一种语言。
任务是平台的处理支柱,我们认为您将找到一些惊人的方法来使用它们。
实时警报和通知
我们公司的座右铭是,我们的团队永远不必查看仪表板即可知道出了什么问题。监控和警报对任何应用程序平台都至关重要,我们也不例外。
InfluxDB 2.0包括一个强大的监控和警报系统,该系统基于与任务和Flux相同的技术。我们的原生用户界面提供了一种快速定义数据阈值和死人警报的方法,但如果您需要更高的灵活性,您可以使用底层任务系统构建您自己的自定义警报。

InfluxDB 和 Flux 可让您向各种端点发送警报
来自这些警报的通知可以发送到任意数量的外部系统,包括 PagerDuty、Slack、Microsoft Teams、电子邮件、MQTT 或你控制的自定义 HTTP 终结点(webhook)。我们提供直观的用户界面来定义和管理这些警报,但通过 UI 提供的每一点功能都通过我们的 API 公开,因此您可以构建适合您的自动化。
具有异常良好工具的通用 API
时间是最终的稀缺资源,开发人员经常在易用性与未来的功能和灵活性之间取得平衡,这是很常见的。在 InfluxDB 2.0 中,我们希望让它变得非常简单,同时也让我们的社区相信,随着他们的用例的发展和使用的增长,我们已经为您做好了准备。
我们的下一代平台是围绕单个通用 API 构建的。无论您是在笔记本电脑上本地构建应用程序,还是扩展到全球数百万用户,构建应用程序的 API 都是相同的。
这也使我们能够提供一套功能强大的命令行工具和跨10种语言的特定于语言的客户端库,以及适用于所有产品的SDK。如果您正在构建应用程序,那么使用 InfluxDB 启动和运行的最快方法是通过我们的一个客户端库。

InfluxDB 客户端库提供多种语言版本
无论您现在正在构建什么,或者将来需要什么样的规模,您都可以放心,您不需要重写应用程序来利用InfluxDB的强大功能。
通过 InfluxDB 堆栈和模板实现现代 GitOps 工作流
Kubernetes已经接管了世界,它带来了GitOps工作流的兴起,使管理和部署应用程序就像签入代码一样简单。InfluxDB 2.0 旨在利用 InfluxDB 堆栈和模板无缝集成到您的 GitOps 部署策略中。
使用命令行工具,您可以通过声明性配置和基于 git 的更改管理来快速管理平台中所有资源的状态。这还允许您构建功能强大的持续集成和部署管道,使部署(更重要的是回滚)更改变得轻松。
该技术为InfluxDB模板功能提供支持,该功能为各种流行技术提供开箱即用的全栈监控。InfluxDB模板是免费使用的,模板库继续增长,因为专家希望与他人分享他们的专业知识。您可以利用InfluxDB社区的集体知识,同时保持扩展和自定义模板的自由,以满足您的确切需求。认为你有正确的东西吗?您也可以贡献自己的专业知识!
InfluxDB Template Gallery
InfluxDB 2.0 允许您自信地部署更改,站在专家的肩膀上,让您专注于构建应用程序。
我们从这里走向何方
正如我在本文开头所说,此版本代表了我们的工程团队在近两年的参与和倾听我们社区方面的大量辛勤工作,但这仅仅是个开始。展望未来,您可以期待一些事情。我们计划标准化我们的发布节奏,以便社区知道何时需要新功能和错误修复。
我们的InfluxDB开源路线图将开始专注于解锁需要本地部署软件的用例,但继续与InfluxDB平台的其他部分(包括InfluxDB Cloud)结合使用。寻找简单的方法来解锁数据复制和聚合到云,以及更多在边缘引入和分析数据的方法。
我们对开源软件的未来感到非常兴奋,并为我们令人惊叹的社区感到谦卑,这些社区帮助我们构建了出色的软件。我们希望您加入我们的旅程,并在GitHub或我们的社区论坛和Slack上打招呼。



