python小结(七)
技术性问题
简述函数式编程
函数式编程更加强调程序执行的结果而非执行的过程,倡导利用若干简单的执行单元让计算结果不断渐进,逐层推导复杂的运算,而不是设计一个复杂的执行过程。 – wiki
https://www.jianshu.com/p/856475c7fa01
https://www.liaoxuefeng.com/wiki/1016959663602400/1017329367486080
概念: 1、函数是一等公民。所谓“一等公民”,指的是函数与其他数据类型一样,处于平等地位,可以复制给其他变量,也可以作为参数,传入另一个函数,或者作为别的函数的返回值。 2、不可改变量。在函数式编程中,我们通常理解的变量在函数式编程中也被函数代替了:在函数式编程中变量仅仅代表某个表达式。这里说的‘变量’是不能被小改的。所有的变量只能被赋值一次初值 3、map & reduce 他们是最常用的函数式编程 >>> def f(x): ... return x * x ... >>> r = map(f, [1, 2, 3, 4, 5, 6, 7, 8, 9]) >>> list(r) [1, 4, 9, 16, 25, 36, 49, 64, 81] # reduce把一个函数作用在一个序列[x1, x2, x3, ...]上,这个函数必须接收两个参数,reduce把结果继续和序列的下一个元素做累积计算,其效果就是: >>> from functools import reduce >>> def add(x, y): ... return x + y ... >>> reduce(add, [1, 3, 5, 7, 9]) 25 特性: 函数是 “一等公民” 只用 “表达式”,不用 “语句” 没有 “副作用” 不修改状态 引用透明(函数运行只靠参数)
什么是匿名函数,有什么局限性
lambda 表达式是 Python 中创建匿名函数的一个特殊语法. 我称 lambda 语法本身为 lambda 表达式,而它返回的函数我称之为 lambda 函数。或者称为匿名函数。 Python 的 lambda 表达式允许在一行代码中创建一个函数并传递。 >>>def square(x) : # 计算平方数 ... return x ** 2 ... >>> map(square, [1,2,3,4,5]) # 计算列表各个元素的平方 [1, 4, 9, 16, 25] >>> map(lambda x: x ** 2, [1, 2, 3, 4, 5]) # 使用 lambda 匿名函数 [1, 4, 9, 16, 25] # 提供了两个列表,对相同位置的列表数据进行相加 >>> map(lambda x, y: x + y, [1, 3, 5, 7, 9], [2, 4, 6, 8, 10]) [3, 7, 11, 15, 19] lambda 表达式可以写出非常简练的代码,但是缺点也非常明显:难于理解,降低了可读性和性能。 lamda优点: 代码简洁 不增加额外变量 lambda 表达式与命名函数的主要不同点: 可以立刻传递(无需变量) 在内部只能包含一行代码 自动返回结果 既没有文档字符串, 也没有名称
如何捕捉异常,常用的异常处理机制有哪些
捕捉异常可以使用try/except语句。try/except语句用来检测try语句块中的错误,从而让except语句捕获异常信息并处理。 如果你不想在异常发生时结束你的程序,只需在try里捕获它。 try: <语句> #运行别的代码 except <名字>: <语句> #如果在try部份引发了'name'异常 except <名字>,<数据>: <语句> #如果引发了'name'异常,获得附加的数据 else: <语句> #如果没有异常发生 sys模块获取异常 另一种获取异常信息的途径是通过sys模块中的exc_info()函数。该函数回返回一个三元组:(异常类,异常类的实例,跟中记录对象)。
copy() 和 deepcopy() 的区别
浅复制:仅拷贝基本数据类型,字典 copy 方法和copy.copy()方法,也是浅复制; 深复制:拷贝数据类型和引用,计算机开辟一块新内存用于存放复制对象。
函数装饰器有什么作用 **
装饰器本质上是一个Python函数,它可以让其他函数在不需要做任何代码变动的前提下增加额外功能,装饰器的返回值也是一个函数对象。它经常用于有切面需求的场景,比如:插入日志、性能测试、事务处理、缓存、权限校验等场景。装饰器是解决这类问题的绝佳设计,有了装饰器,我们就可以抽离出大量与函数功能本身无关的雷同代码并继续重用。概括的讲,装饰器的作用就是为已经存在的对象添加额外的功能。 # 测试代码运行时间的装饰器 import time def cal_time(func): def wrapper(*arg, **kwargs): t1 = time.time() result = func(*arg, **kwargs) t2 = time.time() print('%s running time: %s secs.'%(func.__name__, t2 - t1)) return result return wrapper
新式类和旧式类的区别,如何确保使用的是新式类
1、新式类都从object继承,经典类不需要。 2、新式类的MRO(method resolution order 基类搜索顺序)算法采用C3算法广度优先搜索,而旧式类的MRO算法是采用深度优先搜索 3、新式类相同父类只执行一次构造函数,经典类重复执行多次。 在Python 3.x中取消了经典类,默认都是新式类,并且不必显式的继承object: class Person(object): pass class Person(): pass class Person: pass 三种写法并无区别,推荐第一种
简述Python的作用域以及Python搜索变量的顺序
python中的作用域分4种情况: (1)L:local,局部作用域,即函数中定义的变量; (2)E:enclosing,嵌套的父级函数的局部作用域,即包含此函数的上级函数的局部作用域,但不是全局的; (3)G:globa,全局变量,就是模块级别定义的变量; (4)B:built-in,系统固定模块里面的变量,比如int, bytearray等。 搜索变量的优先级顺序依次是:局部作用域>外层作用域>当前模块中的全局>python内置作用域,也就是LEGB。
简述 new 和 ____init____的区别
__init__是初始化方法,创建对象后,就立刻被默认调用了,可接收参数 1、__new__至少要有一个参数cls,代表当前类,此参数在实例化时由Python解释器自动识别 2、__new__必须要有返回值,返回实例化出来的实例,这点在自己实现__new__时要特别注意,可以return父类(通过super(当前类名, cls))__new__出来的实例,或者直接是object的__new__出来的实例 3、__init__有一个参数self,就是这个__new__返回的实例,__init__在__new__的基础上可以完成一些其它初始化的动作,__init__不需要返回值 4、如果__new__创建的是当前类的实例,会自动调用__init__函数,通过return语句里面调用的__new__函数的第一个参数是cls来保证是当前类实例,如果是其他类的类名,;那么实际创建返回的就是其他类的实例,其实就不会调用当前类的__init__函数,也不会调用其他类的__init__函数。 class A: def __init__(self): print('this is init method', self) def __new__(cls): print('this is cls`s id', id(cls)) print('this is new method', object.__new__(cls)) return object.__new__(cls) a = A() print('this is Class A of id', id(A)) # this is cls`s id 94331320742352 # this is new method <__main__.A object at 0x7efd147af100> # this is init method <__main__.A object at 0x7efd147af100> # this is Class A of id 94331320742352 init 和 new中的 self 和 cls 返回值的地址都一样 返回值是对象 cls 和 类id 一样,说明指向同一类
Python的垃圾回收机制 **
引用计数、标记清除、分代回收
1. 引用计数
class Pyobj: def __del__(self): print('对象被销毁') print(1) obj = Pyobj() obj = 6 # 让变量obj指向其他对象 print(2) # 1 # 对象被销毁 # 2优点:
- 简单
- 实时性高,只要计数为0,对象就被销毁,内存被释放,回收内存的时间就会平摊到了平时
缺点:
* 为了维护引用计数消耗了很多资源 * 循环引用,会导致内存泄露# 循环引用 list1 = [] list2 = [] list1.append(list2) list2.append(list1)list1 和 list2 的引用计数永远大于 0,除非手动操作,他们不可能被GC回收。
引用计数,并不能解决所有的问题,一旦出现了循环引用,那么,这些对象的引用次数永远都是大于0的,但是这些对象都是不可用的垃圾数据。
import gc class DictA(dict): def __del__(self): print('DictA对象被销毁') class DictB(dict): def __del__(self): print('DictB对象被销毁') a = DictA() b = DictB() a['b'] = b # 循环引用 b['a'] = a a = 1 b = 1 print('ok') # ok # DictA对象被销毁 # DictB对象被销毁 # 由于存在循环引用,因此,内存中DictA对象的引用计数是2,当a = 1被执行时,引用计数减少为1,但仍然大于0,不会被回收,DictB的对象同样如此标记清除的原理
标记清除可以处理这种循环引用的情况,它分为两个阶段
第1阶段,标记阶段
GC会把所有活动对象打上标记,这些活动的对象就如同一个点,他们之间的引用关系构成边,最终点和边构成了一个有向图,如下图所示
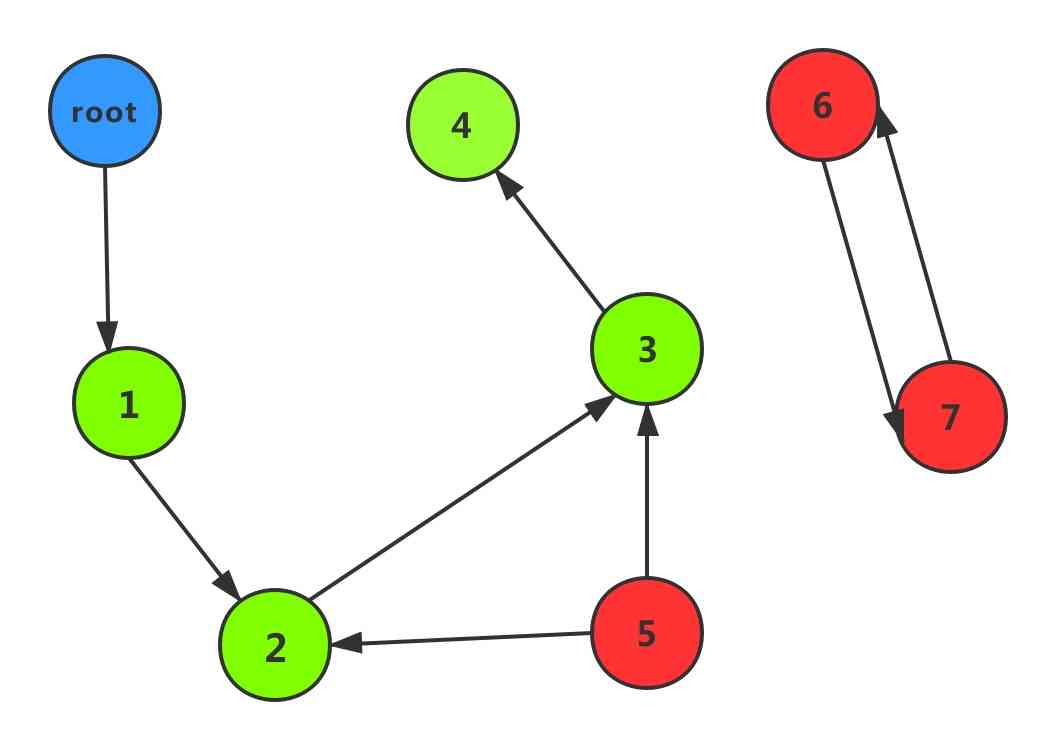
第2阶段,搜索清除阶段
从根对象(root)出发,沿着有向边遍历整个图,不可达的对象就是需要清理的垃圾对象。这个根对象就是全局对象,调用栈,寄存器。
在上图中,从root出发后,可以到达 1 2 3 4,而5, 6, 7均不能到达,其中6和7互相引用,这3个对象都会被回收。
分代回收建立标记清除的基础之上,是一种以空间换时间的操作方式。标记清除可以回收循环引用的垃圾,但是,回收的频次是需要控制的
分代回收,根据内存中对象的存活时间将他们分为3代,新生的对象放入到0代,如果一个对象能在第0代的垃圾回收过程中存活下来,GC就会将其放入到1代中,如果1代里的对象在第1代的垃圾回收过程中存活下来,则会进入到2代。
分代回收的触发机制
import gc print(gc.get_threshold()) # (700, 10, 10) ''' 当分配对象的个数减去释放对象的个数的差值大于700时,就会产生一次0代回收 10次0代回收会导致一次1代回收 10次1代回收会导致一次2代回收 对于第0代的对象来说,他们很可能就被使用一次,因此需要经常被回收。 经过一轮一轮的回收后,能够活着成为第2代的对象,必然是那些使用频繁的对象,而且他们已经存活很久的时间了,大概率的,还会存活很久,因此,2代回收的就不那么频繁, '''import gc gc.set_threshold(600, 10, 5) print(gc.get_threshold()) # 经过了上面的设置,0代和2代的回收会更加频繁
Python中的 @property 有什么作用?如何实现成员变量的只读属性?
python的@property是python的一种装饰器,是用来修饰方法的
我们可以使用@property装饰器来创建只读属性,@property装饰器会将方法转换为相同名称的只读属性,可以与所定义的属性配合使用,这样可以防止属性被修改。
1.修饰方法,是方法可以像属性一样访问。
class DataSet(object): @property def method_with_property(self): ##含有@property return 15 def method_without_property(self): ##不含@property return 15 l = DataSet() print(l.method_with_property) # 加了@property后,可以用调用属性的形式来调用方法,后面不需要加()。 print(l.method_without_property()) #没有加@property , 必须使用正常的调用方法的形式,即在后面加() # 15 # 152.与所定义的属性配合使用,这样可以防止属性被修改。
class DataSet(object): def __init__(self): self._images = 1 self._labels = 2 #定义属性的名称 @property def images(self): #方法加入@property后,这个方法相当于一个属性,这个属性可以让用户进行使用,而且用户有没办法随意修改。 return self._images @property def labels(self): return self._labels l = DataSet() #用户进行属性调用的时候,直接调用images即可,而不用知道属性名_images,因此用户无法更改属性,从而保护了类的属性。 print(l.images) # 加了@property后,可以用调用属性的形式来调用方法,后面不需要加()。 # 1
*args 和 **kwargs 分别代表什么
args和kwargs是python中的可变参数:args表示任意多个无名参数,返回一个tuple;kwargs表示关键字参数,返回一个dict。
有用过 with statement 吗?他的好处是什么?具体如何实现?
with语句的作用是通过某种方式简化异常处理,它是所谓的上下文管理器的一种
with语句会在嵌套的代码执行之后,自动关闭文件。这种做法的还有另一个优势就是,无论嵌套的代码是以何种方式结束的,它都关闭文件
在一个二维数组中,每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序。请完成一个函数,输入这样的一个二维数组和一个整数,判断数组中是否含有该整数。
# 因为数组是有序的 可以从数组左下角开始找 然后往上移动 class Solution: # array 二维列表 def find(self, target, array): for i in range(len(array) - 1, -1, -1): if target == array[i][0]: return True elif target > array[i][0]: for j in range(len(array[0])): # len(array[0]) 表示小数组的长度 if target == array[i][j]: return True else: return False array = [[1,2,8,9],[2,4,9,12],[4,7,10,13],[6,8,11,15]] s = Solution() print(s.find(8, array))



