python小结(三)
字符串相关操作
in ,not , is
串取值方法:可以通过下标进行取值,切片
endswith、startswith、isalnum、isalpha方法:
#isalnum判断输入的字符串是否包含数字和字母
#isalpha判断输入的字符串是否是英文字母,返回结果为布尔值
判断输入的字符串是否为数字:isdigit()
#去除空格: strip()
字符串的join方法:
#join是用来通过 某个字符串 拼接 一个可迭代对象的每个元素—>join(可迭代对象参数类型)
#另一种方法将列表转换为字符串
替换replace字符串
查找find,index字符串
切割字符串spilt,返回结果类型为list
字符串随机生成大小写字母、数字 : # import string
count 计数
字符串中大小写字母的判断与转换 #islower() isupper()
1. 如何python的可变与不可变数据类型
python中的不可变数据类型,不允许变量的值发生变化,如果改变了变量的值,相当于是新建了一个对象,而对于相同的值的对象,在内存中则只有一个对象,内部会有一个引用计数来记录有多少个变量引用这个对象;
可变数据类型,允许变量的值发生变化,即如果对变量进行append、+=等这种操作后,只是改变了变量的值,而不会新建一个对象,变量引用的对象的地址也不会变化,不过对于相同的值的不同对象,在内存中则会存在不同的对象,即每个对象都有自己的地址,相当于内存中对于同值的对象保存了多份,这里不存在引用计数,是实实在在的对象。
2. 将”hello world”转换为首字母大写”Hello World”
a = 'hello world'
a.capitalize()
a.title()3. 如何检测字符串中只含有数字
In [74]: s = '1231413354'
In [76]: d = '3213dasd'
In [77]: d.isalnum()
Out[77]: True
In [78]: d.isdigit()
Out[78]: False
In [79]: s.isdigit()
Out[79]: True
4. 将字符串”ilovechina”进行反转
In [83]: a = 'ilovechina'
In [84]: a[::-1]
Out[84]: 'anihcevoli'5. Python 中的字符串格式化方式
% 和 format()6. 有一个字符串开头和末尾都有空格,比如“ adabdw ”,要求写一个函数把这个字符串的前后空格都去掉。
In [87]: a = ' adabdw '
In [88]: a.strip()
Out[88]: 'adabdw'7. 获取字符串”123456“最后的两个字符
In [89]: a = '123456'
In [90]: a[-2:]
Out[90]: '56'
8. 一个编码为 GBK 的字符串 S,要将其转成 UTF-8 编码的字符串,应如何操作
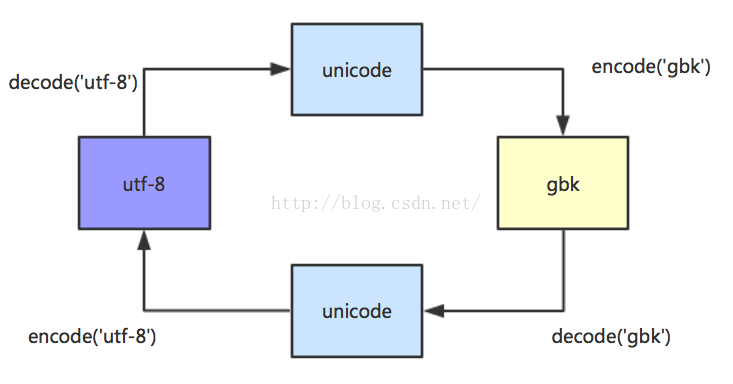
In [135]: s = '你好'
In [136]: s.encode('gbk')
Out[136]: b'\xc4\xe3\xba\xc3' # 发现是4个字符,说明gbk是用两个字节表示一个汉字
In [137]: s.encode('gbk').decode('gbk')
Out[137]: '你好'
In [138]: s.decode()
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-138-036e9cb0ee35> in <module>
----> 1 s.decode()
AttributeError: 'str' object has no attribute 'decode'
# 无法解码出来,说明中文的默认解码方式是utf-8' \硬盘中一般编码都是uft-8\,而在内存中采用*unicode*编码方式。**
python中的str其实显示的就是读取unicode,str的内存格式就是unicode,所以理解为str就是unicode,unicode就是str。
另外而utf-8与unicode编码中的字符部分的编码方式是一样的,所以英文显示没有区别。
9. s=”info:xiaoZhang 33 shandong”,用正则切分字符串输出[‘info’, ‘xiaoZhang’, ‘33’, ‘shandong’], a = “你好 中国 “,去除多余空格只留一个空格。
In [151]: s
Out[151]: 'info:xiaoZhang 33 shandong'
In [152]: re.findall('[^:\s]+',s)
Out[152]: ['info:xiaoZhang', '33', 'shandong']
# \s 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。
In [153]: re.findall('[a-zA-Z0-9]+',s)
Out[153]: ['info', 'xiaoZhang', '33', 'shandong']



